Buckets
Buckets are containers for tables in Storage. They are further organized into the following two stages:
- in --- for input data (usually data source connector results)
- out --- for processed data (usually results of transformations or applications)
The distinction between the input and output stages is purely conventional differentiation between raw and processed data. When creating a new bucket, select one of the stages and a suitable database backend based on its properties. For information on how to load data into Storage, see the corresponding part of our tutorial.
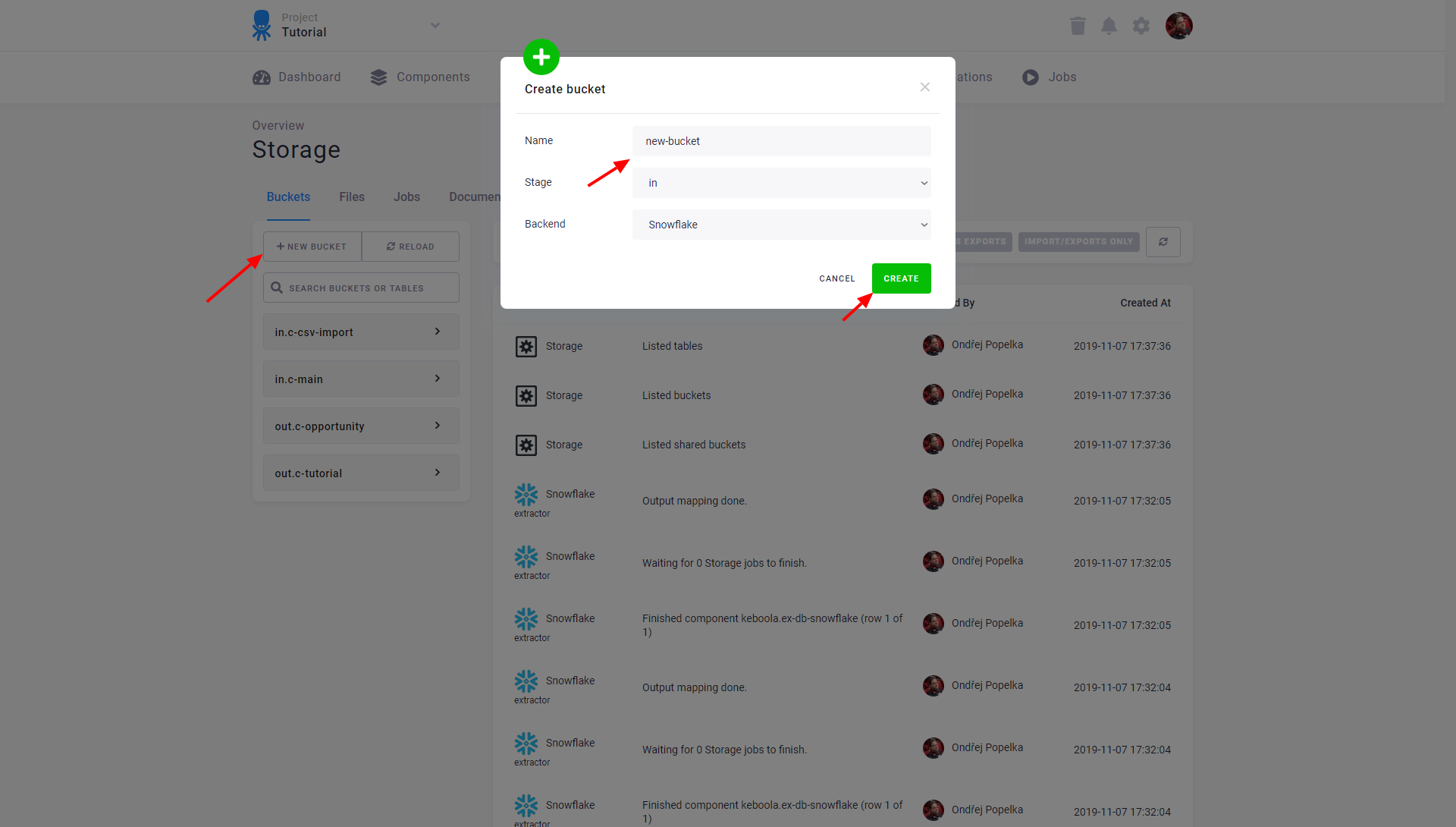
To review information about an existing bucket, hover over the bucket name and select Bucket detail:
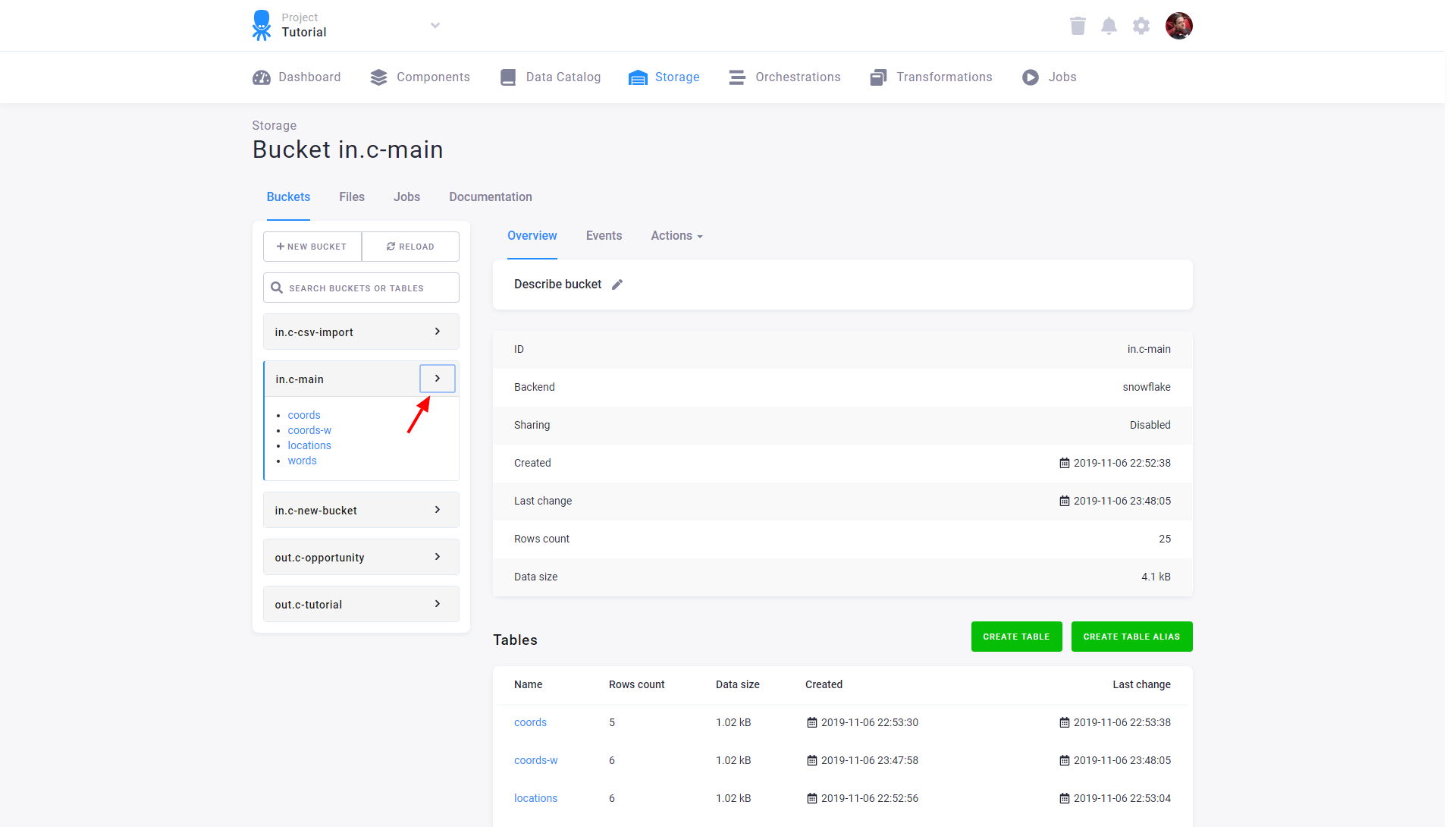
Apart from being used for organizing tables, buckets can also be used for sharing tables.